[AINews] Apple's OpenELM beats OLMo with 50% of its dataset, using DeLighT • ButtondownTwitterTwitter
Chapters
AI Discord Recap
Open-Source LLM Ecosystem Expansion
Small-Scale Model Optimization Insights and Downstream Applications
Skunkworks AI Discord
User Suggestions and Discussions in Unsloth AI Discord Channel
Multi-GPU Efficiency and Kernel Optimization Discussion
LM Studio and ROCm Technology Discussion
Challenges in Custom GPT for SQF in Arma 3
Discussion on Research and AI Models
LAION Research: Revolutionizing Visual Representation Learning
Contrastive Learning Complexity and Fast Training
modular Development Updates
Latent Space Discussions
Nathan Lambert Interconnects Discussion
AI Discord Recap
AI Discord Recap
A summary of Summaries of Summaries
-
Extending LLM Context Lengths
- Discussions on Llama 3's capabilities and mixed opinions compared to GPT-4. Excitement over extending Llama 3's context length to 96k tokens for the 8B model using techniques like PoSE. Tweet thread.
- The EasyContext project aims to extrapolate LLM context lengths to 1 million tokens.
-
Optimizing LLM Training and Deployment
- Nvidia's Nsight Compute CLI for kernel profiling and optimizing CUDA code for LLM training.
- Interest in finetuning large language models for domain-specific gains. Examples like Meditron for medical applications. Discussions on data synthesis strategies using tools like Argilla's Distilabel, and challenges of multi-document, long-context finetuning.
Open-Source LLM Ecosystem Expansion
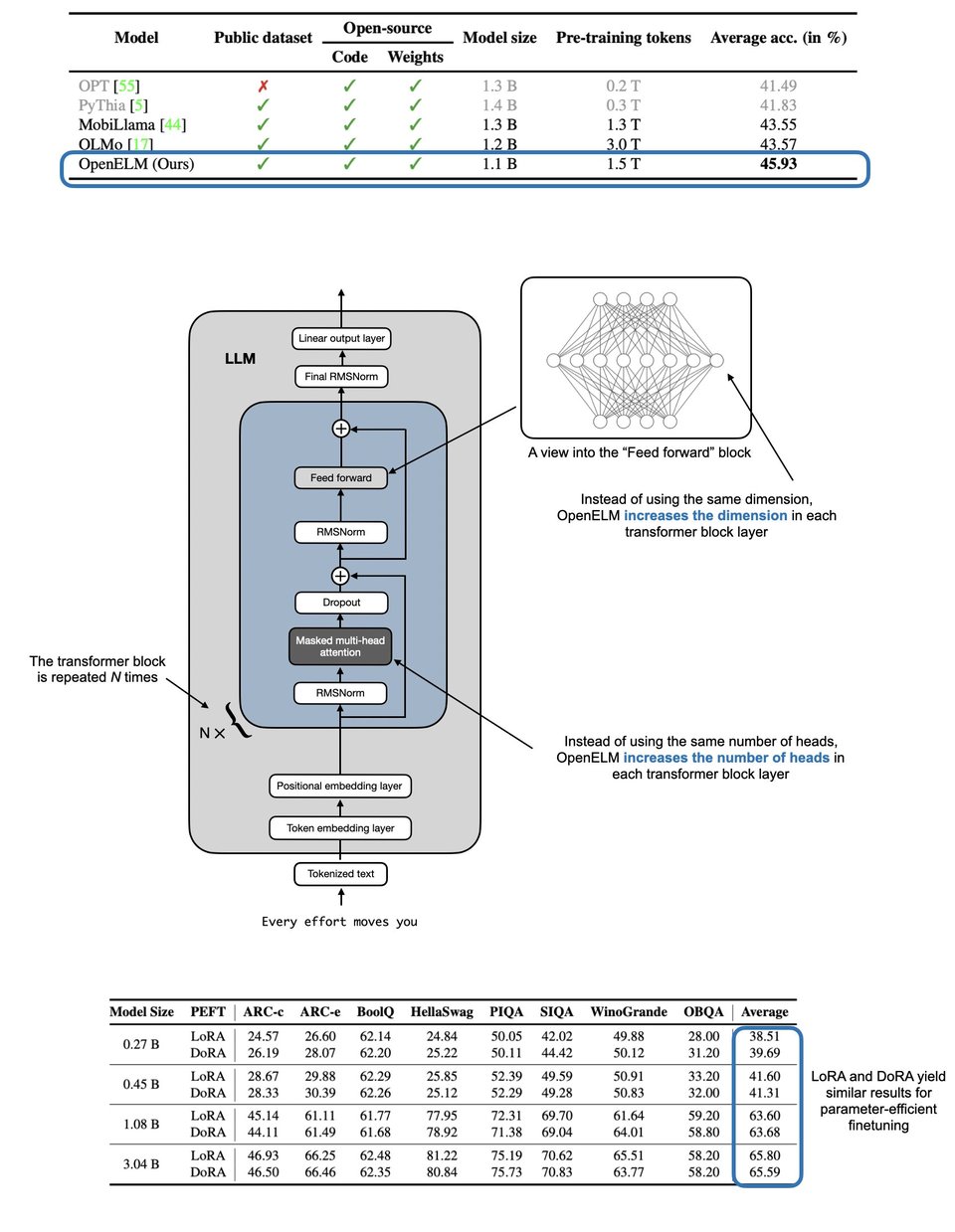
Apple's Surprise Entry into Open-Source Models:
Apple's release of OpenELM, a family of efficient open-source language models ranging from 270M to 3B parameters, caught the AI community by surprise. The move marked a shift from Apple's traditionally proprietary approach, with the 270M model quickly gaining attention on Hugging Face.
BioMistral is introduced:
BioMistral is introduced, leveraging Mistral for pretrained medical LLMs.
Mozilla's llamafile project:
The llamafile project enables distributing and running LLMs locally with high performance.
Dify emerges as an open-source LLM app development platform:
Dify emerges as an open-source LLM app development platform combining AI workflows and model management.
Small-Scale Model Optimization Insights and Downstream Applications
Performance Parity Presumption: The discussion touched on how the phi-3-mini-128k model compares to the Llama-3-8B, highlighting the importance of pre-training data in model benchmarking.### Delta Decision's Dual Nature: There was a debate on the efficacy of delta rule linear attention in structured operations versus parallelizable ones, referencing a ManifestAI blog post.### Testing Through a Tiny Lens: Members emphasized real-world application testing over traditional 'needle in the haystack' tests for long-context language models.### Prompt Loss Ponderings: Questions were raised about the lack of study on masking user prompt loss during supervised fine-tuning despite its common use in language model training.### Five is the GSM8K Magic Number: Consensus suggested using 5 few-shot examples aligned with the Hugging Face leaderboard criteria for GSM8K models.### VLLM Version Vivisection: Data Parallel (DP) was identified as a hindrance in updating VLLM, favoring Tensor Parallel (TP) for smoother upgrades.### Calling Coders to Contribute: The lm-evaluation-harness was found lacking a register_filter function, prompting a call for contributions to enhance its utility.### Brier Score Brain Twister: An anomaly in ARC evaluation data prompted a reevaluation of the Brier score function for error-free assessments.### Template Tête-à-Tête: Interest was shown in the chat templating branch in Hailey's branch, with inquiries into its development progress.
Skunkworks AI Discord
The Skunkworks AI Discord section covers various topics discussed within the community. It includes a guide on fine-tuning the Moondream Vision Language Model for CAPTCHA recognition, evaluations of low-cost AI models for Python code generation, an invitation to an AI developer meetup in Toronto, and the introduction of Snowflake Arctic as an enterprise-ready Large Language Model. The section also delves into in-depth discussions on model behavior and AI training methods, including comparisons between reinforcement learning strategies, the impact of training method transitions on model performance, and challenges related to gradient norm spikes during pretraining.
User Suggestions and Discussions in Unsloth AI Discord Channel
Meta Unveils LlaMA-3:
Meta announces the next generation of its LlaMA model series, releasing an 8B model and a 70B model, with a teased upcoming 400B model promising GPT-4 level benchmarks. Interested parties can request access to these models, which are reportedly top of their size classes; the detailed comparison and insights are available in a Substack article.
Open-Sourcing Kolibrify:
A user announces the release of their project Kolibrify, a tool for curriculum training of instruction-following LLMs with Unsloth, designed for PhD research. The tool, aimed at those finetuning LLMs on workstations for rapid prototyping, is available on GitHub.
Innovating with TRL Trainer:
A member is working on implementing laser pruning and potentially freezing with a trl trainer that functions during the evaluation step. The goal is to iteratively increase context length for models while utilizing the same GPU.
No Reinitialization Required for Context Expansion:
The suggestion to increase available context length through model and tokenizer configuration adjustments was made. It was confirmed that these changes do not require reinitialization of the system.
Emoji Expressiveness in Chat:
Members are using emojis in their communication, with comments expressing surprise and delight at the ability to type emojis in the chat.
Multi-GPU Efficiency and Kernel Optimization Discussion
In this section, the group discusses integrating multi-GPU support with NCCL, potential performance improvements like gradient accumulation, and the consideration of not supporting multi-GPU for FP32. They also share strategies for optimizing a layernorm backward kernel without atomics, simplifying the FP32 version of train_gpt2, brainstorming the use of persistent threads and L2 communication for better memory bandwidth exploitation, and discussing the new CUDA concurrent kernel execution model managed by queues for improved memory bandwidth exploitation and reduced latency.
LM Studio and ROCm Technology Discussion
Hardware Advise for LLM Hosting: Recommendations for hosting AI and web applications include having a system with at least 16GB VRAM and possibly using Nvidia's contemporary architecture GPU.
ROCm on Nvidia? Not Quite: Discussion on a member mistakenly using AMD's ROCm preview with an Nvidia GPU resulting in CPU fallback.
ROCm Performance Report: Impressive speeds achieved with ROCm, reaching 30t/s on an eGPU setup, showcasing significant performance capabilities.
High Hopes for AMD Improvements: Community expressing hope and skepticism for AMD's developments in the tech space.
Troubleshooting ROCm Errors: Users troubleshoot errors and compatibility issues, emphasizing the importance of proper driver installation and compatibility with the HIPSDK for success.
Challenges in Custom GPT for SQF in Arma 3
A user is seeking advice for crafting prompts to build a GPT tailored for coding in SQF language for Arma 3. The user uploaded various text files with information, example code, and URLs to assist the GPT model. Another user recommends crafting a prompt to always scan the provided knowledge but cautions that it may limit the programming solution space. The conversation also delves into debates about AI models' logic and tone capabilities, defining intelligence for AI, discussing temporal awareness in AI models, and exploring emergent abilities in Large Language Models (LLMs). Overall, the community engages in in-depth discussions about various AI topics and model performances.
Discussion on Research and AI Models
In this section, various discussions took place related to research and AI models in the Eleuther Discord channel. Users clarified how linear attention works and its benefits, benchmarked different models like phi-3-mini-128k and Llama-3-8B, and examined the practicality of delta rule linear attention. There were also debates on the effectiveness of 'needle in the haystack' tests for long-context language models and the impact of masking user prompt loss during supervised fine-tuning on language models.
LAION Research: Revolutionizing Visual Representation Learning
A novel weakly supervised pre-training method for vision models was highlighted, categorizing pre-training on image-text data as a classification task. This approach achieved a training speed 2.7 times faster than traditional contrastive learning without compromising representation quality. Building on this success, the method's effectiveness was attributed to detecting concepts from alt-text and training a multilabel classifier, resulting in model performance comparable to CLIP in zero-shot scenarios and significantly improved training efficiency. The conversation also touched on the efficacy of text encoders and contrastive learning.
Contrastive Learning Complexity and Fast Training
Contrastive learning, particularly in aligning text encoders, can be computationally expensive, especially when handling noisy alt text. Although achieving a 2.7x speed boost in training was noted, the overall process remains time-consuming. Interest was expressed in exploring VAST possibilities, with a focus on finetuning the Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset. Community discussions also included optimizing local models to avoid looping behavior, integrating Open Interpreter for robot control, and sharing experiences with running the latest Open Interpreter update. Additionally, conversations delved into the benefits of fine-tuning Large Language Models for domain-specific tasks, with mentions of upcoming research papers and insights on AI benchmarks.
modular Development Updates
The modular development updates include various discussions within the community regarding the tinygrad project, software security challenges faced by Modular, and insights into quantum phenomena and machine learning. The section covers a range of topics such as tutorials, documentation visibility, security defenses against supply chain vulnerabilities, and the relationship between machine learning and quantum entanglement visualization. Additionally, there is a comparison between Mojo and Rust, discussions on Mojo function fundamentals, and the challenges and advancements in Mojo programming language. Lastly, the section highlights achievements in Mojo community engagement and excitement for future benchmarks and performance improvements.
Latent Space Discussions
Apple Enters Open Source Space
Apple has released smaller-than-expected models, including a 270M parameter model on Hugging Face. Dify's app development platform gains attention but faces concerns about loops and context scopes. PyTorch introduces Torchtitan for training large language models. OpenAI's SORA video generation model can create detailed videos up to a minute long. Solutions for handling output quotations with Opus's Claude 3 are discussed.
Mixture of Depths Paper
A paper on 'Mixture of Depths' is presented, offering a method to accelerate transformer training. Challenges of deploying Large Language Models (LLMs) are explored, noting that compact LLMs may not outperform larger ones. Insights on how the Mixture of Depths paper can enhance transformer performance are discussed.
Phi-3-mini-4k-instruct Performance
Phi-3-mini-4k-instruct shows mixed results on eq-bench compared to published evaluations. The CPU feature requirements for running llamafile are highlighted, along with potential collaboration opportunities for evaluation methods.
API Focus and Library Ease
Discussions on Tgi's API focus and vllm's ease of use are ongoing. Batch generation capabilities at Hugging Face are debated. Issues with DiscoLM's inference speed are reported, contrasting performance on different systems.
Nathan Lambert Interconnects Discussion
-
Debating Claude’s Capabilities: A discussion on Claude’s RLAIF training and its unique understanding.
-
RLHF vs. KTO in Commercial Deployments: Comparison of Reinforcement Learning from Human Feedback and Knowledge-Targeted Optimization.
-
Transitioning Training Methods for Improved Results: Experience shared on moving from Supervised Fine Tuning to Data Programming by Demonstration to KTO.
-
Complications and Nuance in RLHF: Nuanced aspects of RLHF in relation to evaluation metrics.
-
Understanding Grad Norm Spikes: Inquiry on spikes in gradient norms during pretraining.
FAQ
Q: What is the focus of discussions around extending LLM context lengths in the AI Discord recap?
A: Discussions focus on techniques like PoSE to extend Llama 3's context length to 96k tokens for the 8B model, as well as the EasyContext project aiming to extrapolate LLM context lengths to 1 million tokens.
Q: How is Nvidia's Nsight Compute CLI being utilized in optimizing LLM training and deployment?
A: Nvidia's Nsight Compute CLI is being used for kernel profiling and optimizing CUDA code for LLM training.
Q: What is the significance of Apple's entry into open-source models with OpenELM?
A: Apple's release of OpenELM marks a shift towards open-source language models, with models ranging from 270M to 3B parameters garnering attention in the AI community.
Q: What are some projects like BioMistral, Mozilla's llamafile, and Dify that are introduced in the AI Discord recap?
A: BioMistral leverages Mistral for pretrained medical LLMs, llamafile enables distributing and running LLMs locally with high performance, and Dify emerges as an open-source LLM app development platform combining AI workflows and model management.
Q: What topics are covered in the Skunkworks AI Discord section related to AI model behavior and training methods?
A: Discussions cover comparisons between reinforcement learning strategies, impact of training transitions on model performance, challenges related to gradient norm spikes, and optimizing layernorm backward kernels without atomics.
Q: What is Meta's announcement regarding the LlaMA model series in the AI Discord recap?
A: Meta unveils the next generation of its LlaMA model series, releasing 8B and 70B models and teasing an upcoming 400B model promising GPT-4 level benchmarks.
Q: What were the discussions around Apple's release of smaller models and the challenges of deploying large language models in the AI Discord recap?
A: Discussions focused on Apple's smaller-than-expected models release, Dify's app development platform concerns, PyTorch's Torchtitan introduction, and OpenAI's SORA video generation model capabilities.
Q: What are some of the topics covered in the Eleuther Discord channel regarding linear attention, benchmarks, and practicality of delta rule linear attention?
A: Discussions include clarifications on linear attention benefits, benchmarks comparing phi-3-mini-128k and Llama-3-8B models, and debates on the practicality of delta rule linear attention.
Q: What method for accelerating transformer training was highlighted in the AI Discord recap?
A: The 'Mixture of Depths' paper was presented as a method to accelerate transformer training, with discussions on enhancing transformer performance.
Q: What are some of the key discussions in the Modular development updates section of the AI Discord recap?
A: Discussions cover topics like the tinygrad project, machine learning and quantum entanglement visualization, comparisons between Mojo and Rust, and achievements in Mojo community engagement.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!